Ich habe in den letzten Wochen mehrfach für Kunden die Installation von Graylog durchgeführt, daher habe ich mir gedacht, ich veröffentliche die Installationsanleitung und die Schritte mal auf meinem Blog.
Übersicht und Anmerkungen
Graylog ist eine Software, die in der Lage ist, Logfiles von vielen unterschiedlichen Systemen einzusammeln und zu verarbeiten. Es gibt sie in unterschiedlichen Versionen, die sich im Funktionsumfang und im Preis unterscheiden. Die Variante, die ich hier in der Anleitung installiere, ist die freie und kostenlose Version. Damit kann man schon recht viel erreichen.
Mit Graylog kann ich Logfiles in vielen Varianten und von vielen unterschiedlichen Geräten sammeln, in einer Datenbank speichern und dann auswerten. Das bringt unter anderem den Vorteil, dass ich deutlich länger in die Vergangenheit schauen kann, weil der Speicherplatz für die Logfiles auf den Systemen selbst meist limitiert ist. Wenn ich spezielle Vorfälle vermeiden möchte, oder eine aktive Warnung bekommen möchte, ist dies ebenfalls möglich. Dies könnte z.B. eine Warnung sein, wenn sich jemand versucht mit einem Admin-Account in meiner Domäne anzumelden, wenn ein neuer Administrator erstellt wird oder wenn es mehr als fünf fehlgeschlagene Anmeldungen per SSH auf meinem Linux-System gibt. Tritt dieser Fall auf, kann ich über unterschiedliche Arten und Wege benachrichtigt werden. Das könnte klassisch eine Email sein, ich könnte mich aber auch per Slack oder Teams benachrichtigen lassen. Weiterhin lassen sich Dashboards erzeugen, die z.B. auf einem Monitor in meiner IT-Abteilung den Stand der letzten 24 Stunden zeigen. Der Fantasie sind hierbei keinerlei Grenzen gesetzt.
Graylog und Debian 12 ist zum Zeitpunkt der Erstellung von diesem Artikel (11. März 2024) möglich, einige Anleitungen zeigen allerdings Debian 11 oder 10. Da ich aber einen möglichst langen Wartungszeitraum haben möchte, bevorzuge ich die Version 12. Wir sind aktuell bei Version 12.5.0.
Die Installation von Debian
Die Installation der Basis ist recht einfach, es gibt keine großen Anforderungen oder Besonderheiten. Wichtig ist, dass System entsprechend den Anforderungen zu gestalten und insbesondere bei der Größe der Festplatte(n) eine gute Auswahl zu treffen. In meinem Fall installiere ich das System als ein Standalone Server mit einer 1 TB großen (virtuellen) Festplatte, theoretisch wäre auch die Nutzung von mehreren Systemen im Cluster-Verbund möglich, das würde aber hier den Rahmen vollständig sprengen.
Der Download der aktuellen ISO-Datei ist wie immer unter https://www.debian.org/download möglich. Bei der Installation nutze ich Hyper-V als Basis, hier muss darauf geachtet werden, dass bei der Generation 2 der VM die Secure Boot-Einstellungen so umgestellt werden, dass Debian starten darf.
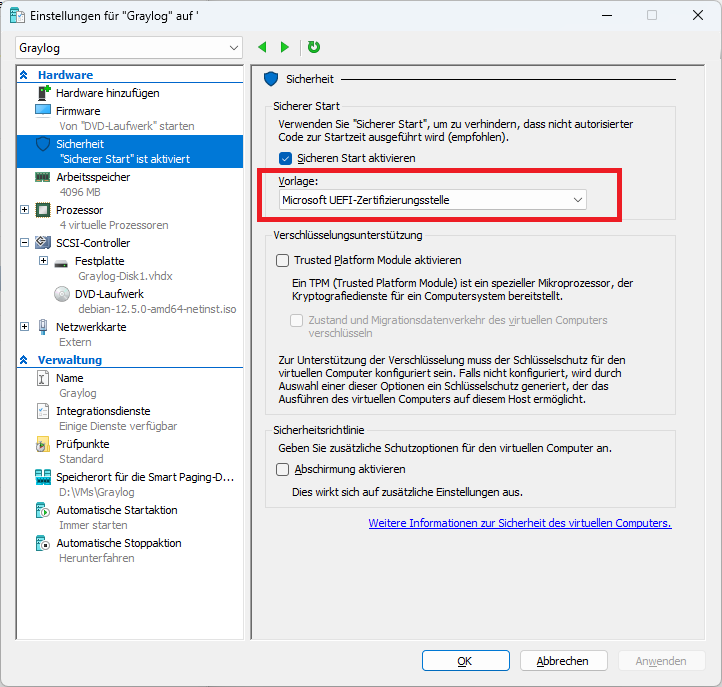
Der Rest der Installation ist recht selbsterklärend. Ich bevorzuge die Systeme in Englisch, und installiere grundsätzlich bei einem Server keinen Desktop, sondern ausschließlich die System-Tools und SSH für eine Administration aus der Ferne.
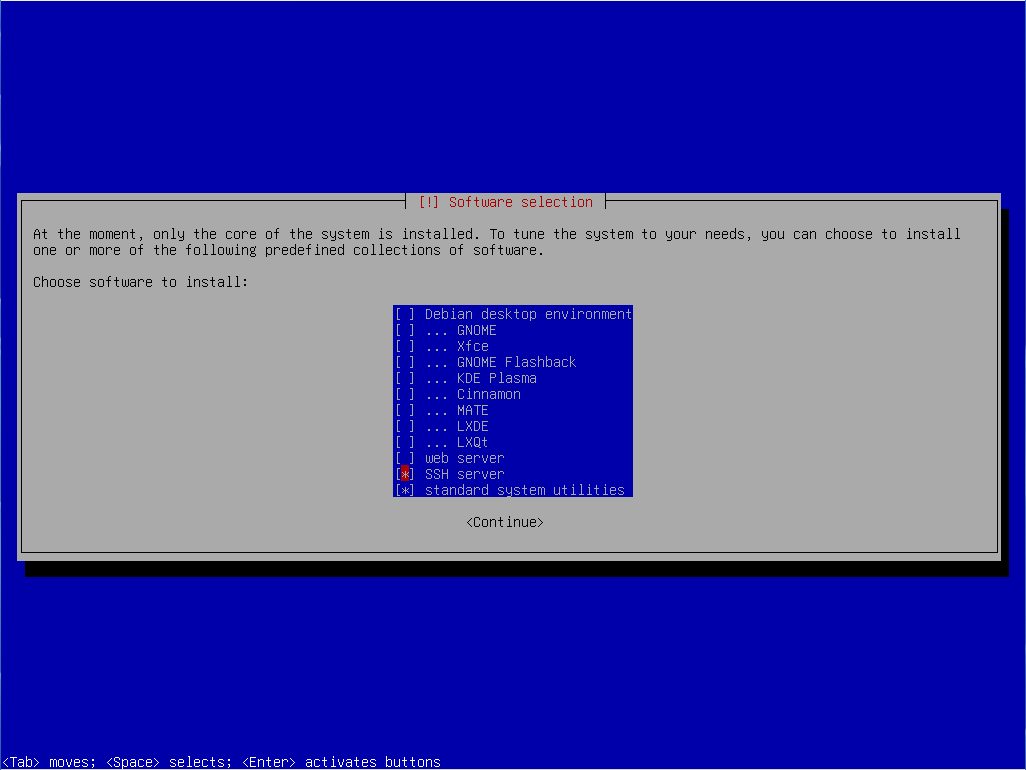
Nach der Grundinstallation melden wir uns an dem System an, die eigentliche Installation kann starten.
Kleiner Tipp vorweg: Ein Snapshot an dieser Stelle kann eine Neuinstallation ersparen, sollte es mal nicht so klappen wie gewünscht. Kostet nix, geht schnell, und spart im besten Fall einige Minuten Arbeit.
Vorbereitungen
Wir benötigen während der Installation ein paar Pakete, die wir als erstes installieren
apt install -y apt-transport-https uuid-runtime pwgen gnupg curlDie Installation von Elasticsearch
Wir beginnen nun mit der Installation von Elasticsearch. Dies ist eine Komponente, mit der wir, wie der Name schon sagt, in unseren Daten suchen können. Graylog arbeitet alternativ auch mit OpenSearch zusammen, ich habe die Installationen aber jeweils mit Elasticsearch gemacht und bisher keine Nachteile oder Probleme feststellen können. Wichtig ist, dass wir die Version 7 installieren, die auch schon verfügbare Version 8 hat in meinen Tests nicht funktioniert.
Als erstes müssen wir den Schlüssel für das Repository hinzufügen und die Paketquellen aktualisieren, damit wir eine Installation vornehmen können.
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | apt-key add -
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | tee /etc/apt/sources.list.d/elastic-7.x.list
apt update && apt install -y elasticsearch=7.10.2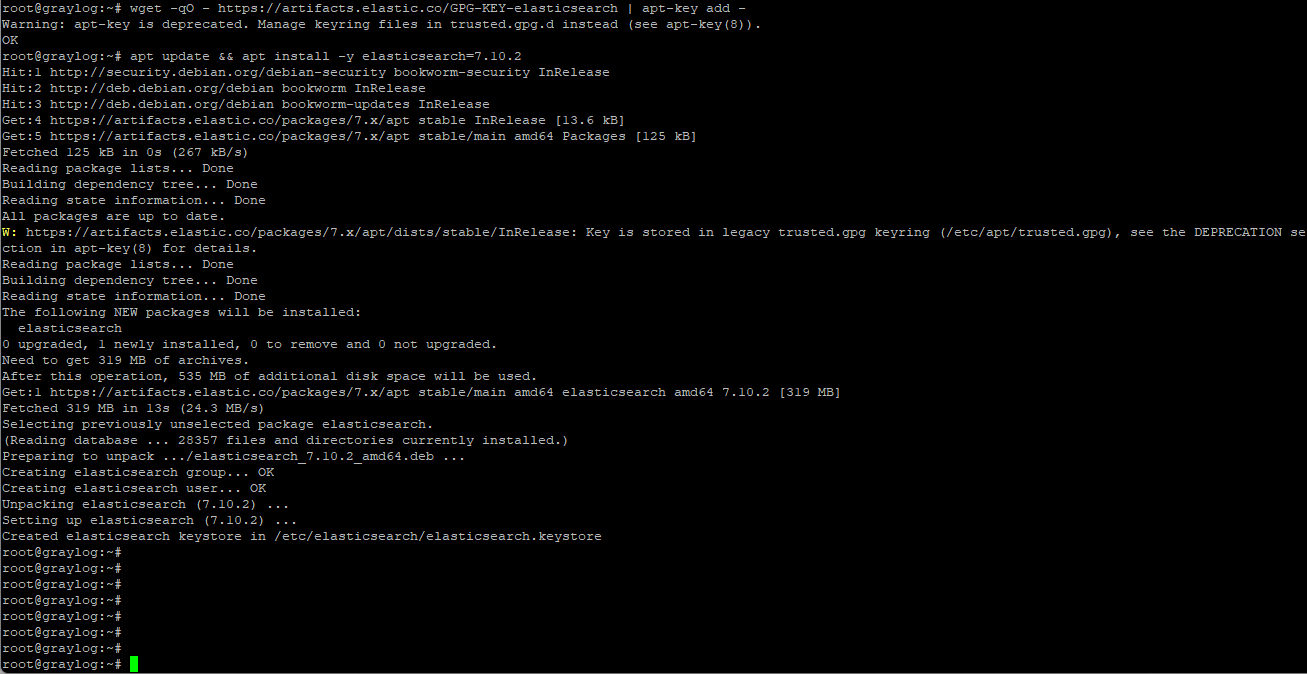
Nachdem die Installation abgeschlossen ist, fügen wir noch ein paar Zeilen Code in die Konfigurationsdatei ein. Dies ist wichtig, damit ein existierenden Pfad für die Logfiles genutzt wird.
echo "cluster.name: graylog
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch" | tee /etc/elasticsearch/elasticsearch.ymlJetzt können wir den Dienst auf Autostart setzen, starten, und danach den Zustand überprüfen. Hier sollte es keine Probleme oder Fehler geben.
systemctl daemon-reload
systemctl enable elasticsearch.service
systemctl restart elasticsearch.service
systemctl --type=service --state=active | grep elasticsearch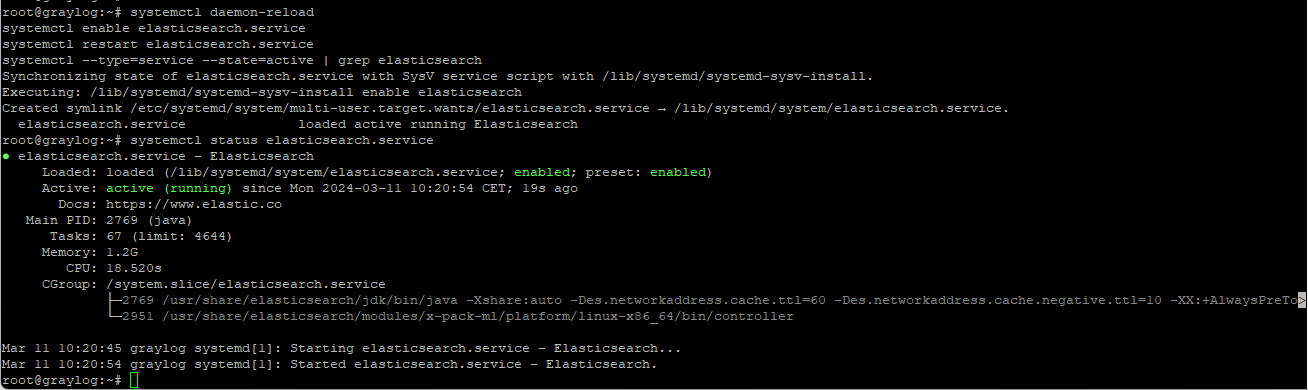
Die Installation von MongoDB
Im nächsten Schritt installieren wir die Datenbank, in die unsere Daten gespeichert werden. Sofern man sich bei der Installation nicht allzu sicher ist, wäre es jetzt nochmal ein guter Zeitpunkt, einen Snapshot der VM zu erzeugen 🙂
curl -fsSL https://www.mongodb.org/static/pgp/server-7.0.asc | gpg --dearmor -o /etc/apt/trusted.gpg.d/mongodb-7.gpg
echo "deb http://repo.mongodb.org/apt/debian $(lsb_release -cs)/mongodb-org/7.0 main" | tee /etc/apt/sources.list.d/mongodb-org.list
apt update && apt install -y mongodb-org mongodb-org-database mongodb-org-server mongodb-org-shell mongodb-org-mongos mongodb-org-tools
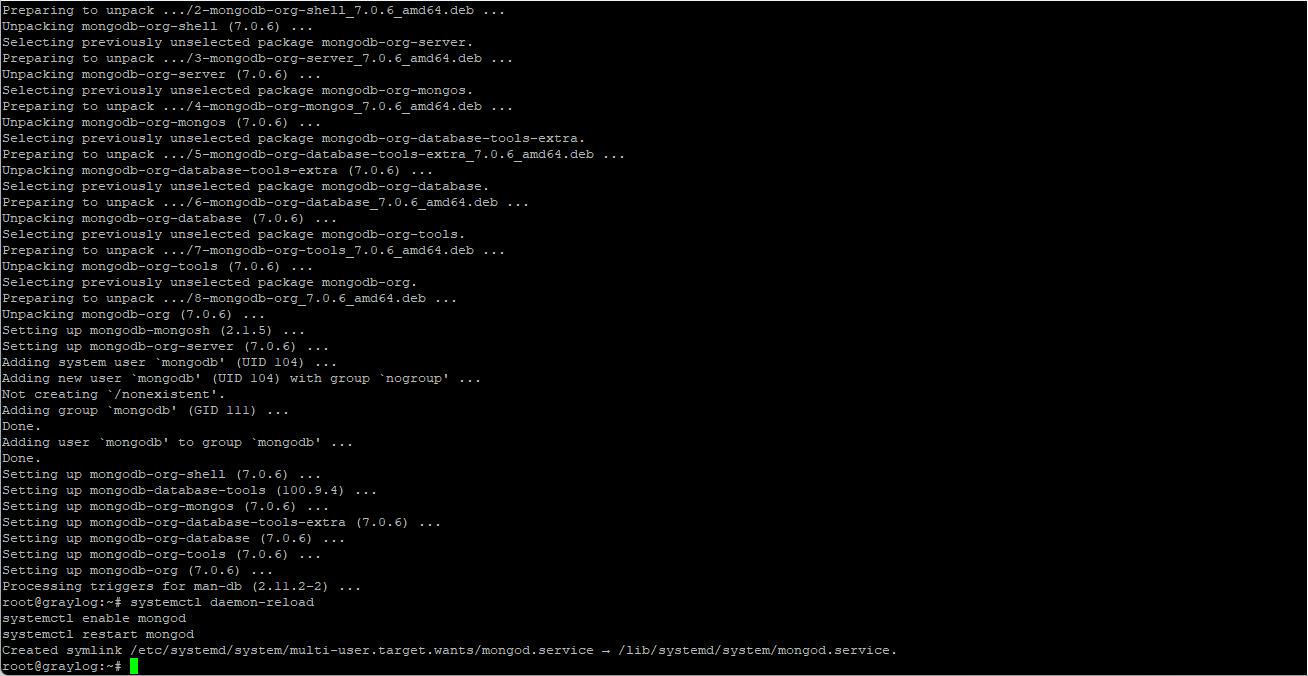
Nach der Installation können wir hier ebenfalls den Dienst auf Autostart setzen, und die Datenbank starten.
systemctl daemon-reload
systemctl enable mongod
systemctl restart mongod
Nun erstellen wir eine neue Datenbank sowie einen Datenbank-Administrator. Hierfür benötigen wir ein komplexes, einmaliges Kennwort. Gute Kennwörter lassen sich z.B. mit diesem Kennwort-Generator erzeugen: https://www.faq-o-matic.net/richtigpferd/
mongoshHiermit wechseln wir in die Shell der Datenbank, und können ab hier die folgenden Befehle absetzen:
use graylog
db.createUser(
{
user: "graylog",
pwd: "Behaglich-Microsofts-Autoritaet-Ueberblick-3",
roles: [ "readWrite", "dbAdmin" ]
}
)
quit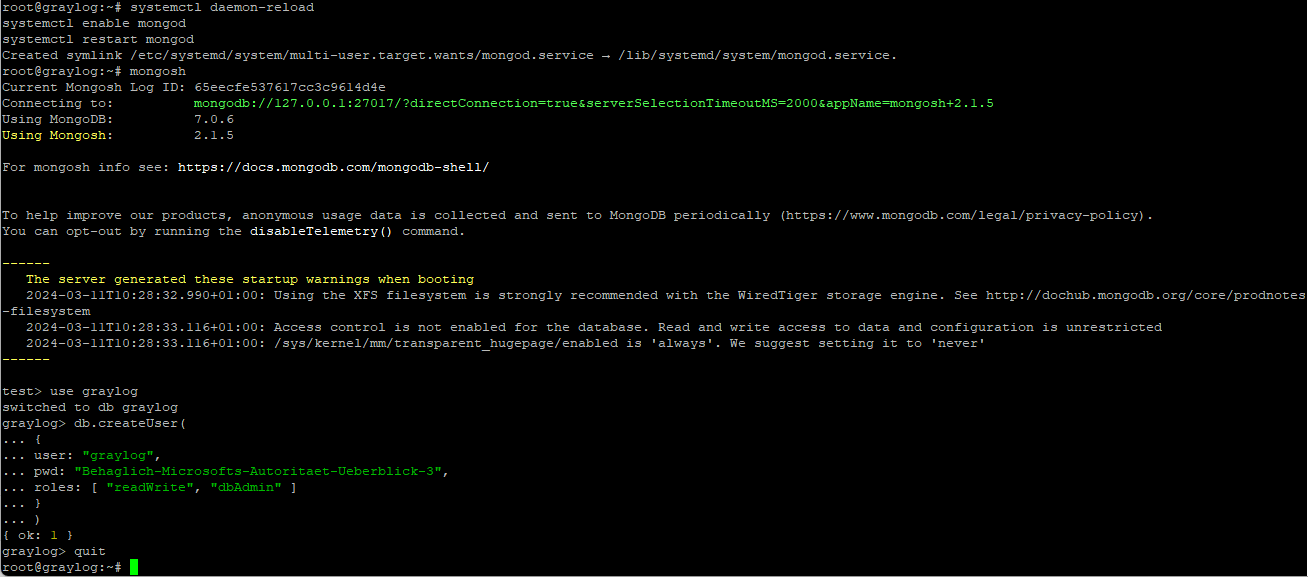
Damit haben wir nun die Installation der Datenbank abgeschlossen. Nun beginnt der letzte Schritt der Installation, die eigentliche Installation von Graylog selbst.
Die Installation von Graylog
Die Installation selbst ist recht einfach, wir brauchen nur die Paketquelle und die Installation des Pakets. Ich nutze in meinem Fall die Version 5.1, mit der Nachfolge-Version 5.2 gibt es scheinbar noch ein Problem, die Anmeldung an der Webkonsole nach der Installation klappt nicht. Version 5.1 läuft sauber und macht das, was es soll.
wget https://packages.graylog2.org/repo/packages/graylog-5.1-repository_latest.deb
dpkg -i graylog-5.1-repository_latest.deb
apt update && apt install graylog-server
Nach der Installation benötigen wir nun zwei Kennwörter. Einmal den Zugang für den Admin-Account für Graylog, und einmal ein starkes Kennwort für die Konfiguration zur Absicherung der Kennwörter. Beginnen wir mit dem Admin-Account.
Der admin-Account
Um das Kennwort für den admin-Account zu setzen, müssen wir das Kennwort in Hash-Form in die Graylog-Konfiguration eintragen. Um das korrekt Format zu haben, kann der folgende Befehl genutzt werden:
echo -n "Enter Password: " && head -1 </dev/stdin | tr -d '\n' | sha256sum | cut -d" " -f1Dieser Befehl fragt das admin-Kennwort ab und gibt es danach in der korrekten Form wieder aus. Unbedingt beide Werte sicher ablegen und speichern!

Secure Passwort
Das zweite Kennwort muss eine gewisse Länge haben, damit es sicher ist. Wir können uns auf der Konsole einfach ein Kennwort ausgeben lassen:
pwgen -N 1 -s 96
Auch das Kennwort bitte sicher speichern und aufbewahren. Sollten wir mal mehr als einen Graylog Server betreiben, muss dieser Wert auf allen Systemen identisch sein.
Die Anpassung der Graylog-Konfiguration
Nachdem wir die Kennwörter generiert haben, können wir die Konfiguration von Graylog anpassen.
nano /etc/graylog/server/server.confIn dieser Datei passen wir ein paar Werte und Optionen an (bitte hier eure Werte eintragen, nicht meine!):
# Passwort_Secret anpassen
password_secret = 6R6DgRZa1d9Glc3pPDd0zkcLDyVe3cygudcZmpioUlBbHQWFoJFzt3YQnASGDYwLG0MbFGZpHgJkZq7liF6Pyjn5cNCKP5cG
# Admin-Kennwort in Hash-Form
root_password_sha2 = dc419a87f5431cc7a8f23a9eaeb643bee1cd8b09d4657cdcddf124d5b8dbe01b
# Email-Adresse des Admins
root_email = "jan@zueschen.eu"
# Eure Zeitzone, damit Logdateien in der korrekten Zeit dargestellt werden. Wichtig!
root_timezone = Europe/Berlin
# Die Bindung, worauf der Dienst im Netzwerk hört
http_bind_address = 0.0.0.0:9000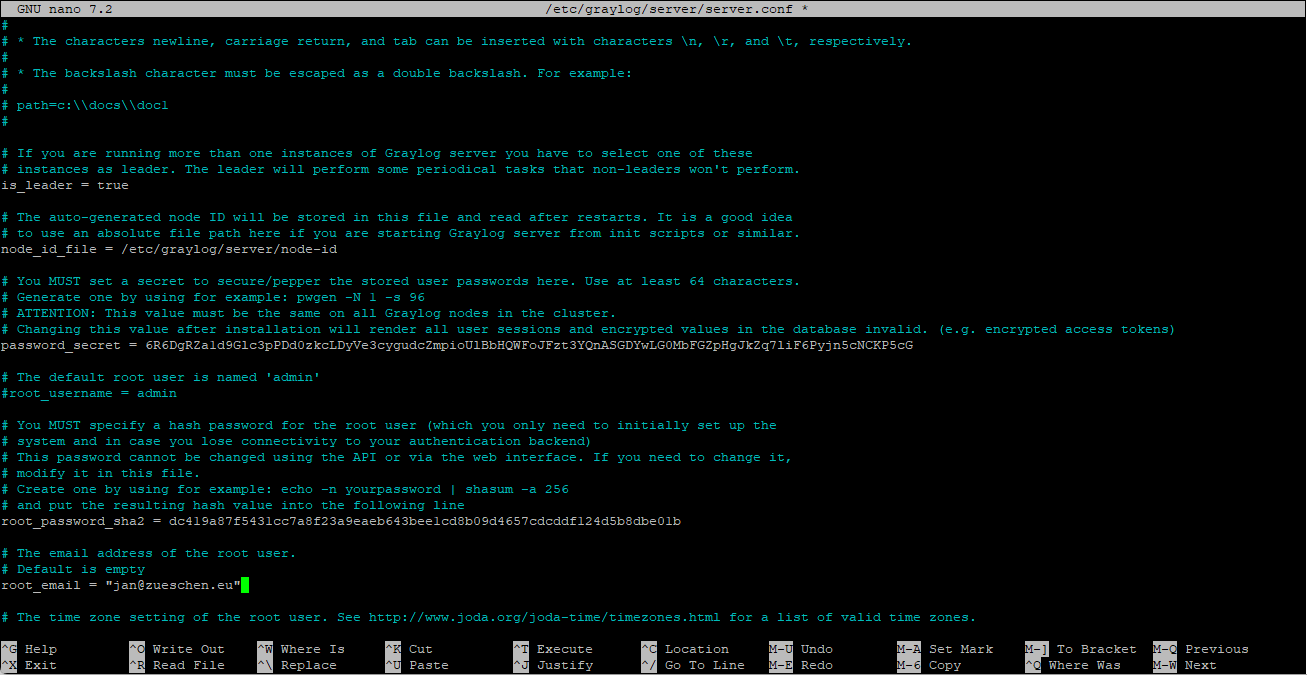
Nachdem die Konfiguration angepasst wurde, können wir den Dienst auf Autostart setzen, und danach starten.
systemctl daemon-reload
systemctl enable graylog-server.service
systemctl restart graylog-server.serviceDer erste Start
Nachdem die Installation abgeschlossen ist, können wir in einen Webbrowser wechseln und die IP-Adresse des Graylog-Servers auf Port 9000 aufrufen. Hat alles geklappt, erwartet uns die folgende Seite:

Hier können wir uns nun mit „admin“ (Groß-Klein-Schreibung beachten!) und dem Kennwort, was wir gewählt haben, anmelden.
Fazit
Die Installation von Graylog ist schnell gemacht, wenn die Pakete und Versionen zueinander passen. Nach der eigentlichen Installation beginnt die Einrichtung und das erste Logging sowie eine erste Auswertung der gesammelten Logdateien. Teil 1 der kleinen Reihe ist hiermit beendet, in Teil 2 geht es weiter mit den ersten Einstellungen und Anpassungen.


Cool, danke. Freue mich auf den zweiten Beitrag. Nutzt du Graylog Open oder welche Lizenz? Mich interessiert vor allem die Anbindung von DCs und die Filterung das nur bestimmte, z.B. Fehlgeschlagene Anmeldungen ins Graylog geschickt werden.
Hi Chris,
ich nutze die freie Variante aktuell, ich habe (noch) keinen Bedarf an einer Lizenz für die Zwecke, die ich brauche.
Die Anbindung von DCs kommt auf jeden Fall noch, bei den Anmeldungen (insbesondere die fehlgeschlagenen) ist es eher so, dass man alles reinpumpt, und dann eine Filterung bzw. eine Alarmierung auf gewünschte Events macht.
Schönen Gruß
Jan
Gibt es bei der freien Variante keine GB pro Tag Beschränkung?
Ich pushe momentan Logs unserer PaloAlto Firewalls in Graylog. Mich würde interessieren, ob ich aus der Message IP Adressen filtern und diese in eine TXT exportieren kann.
Was mit noch aufgefallen ist, dass du Elasticsearch nutzt, es wird aber Opensearch empfohlen.
Graylog 5.0 adds support for OpenSearch 2.x versions. At this time the latest released version is OpenSearch 2.4. We have removed support for Elasticsearch 6.8, which reached its end-of-life date in February 2022. Support for Elasticsearch 7.10 remains in Graylog 5.0, but we recommend users upgrade to OpenSearch.
https://go2docs.graylog.org/5-0/planning_your_deployment/upgrading_to_opensearch.htm